

Каждая компания проходит свой путь. Мы уходили в неоплачиваемый отпуск, распускали штат, работали с фрилансерами — и оставили это в прошлом. Теперь InfoShell занимает 1 место по Москве в Рейтинге Рунета, входит в ТОП-5 Ruward и строит планы на будущее. Что сделало нас одними из лучших на digital-рынке в России и куда движемся дальше? Читайте наш опыт в этой статье.
Взаимодействие — ключ к успеху
Мы общаемся, передаем друг другу опыт в узкопрофильных вопросах, подключаем специалистов из разных отделов — в результате получается многопрофильный подход в сжатые сроки. Общая база документов, митапы по трудно решаемым задачам, открытость сотрудников — каркас взаимодействий.
Мы рушим барьеры на пути у коммуникаций: в частности, софтовые костыли. У нас строго регламентированы корпоративные мессенджеры: видео-чатом стали Hangouts и Zoom, внутри компании чатики в Телеграме, весь внутренний менеджмент в Битриксе. Чтобы не было по 3 чата в 5 разных системах.
Scrum любимый scrum
Переход на процессный подход и Agile дался компании нелегко, но результат очевиден: процесс разработки контролировать стало проще, изменения в проектах уже не так болезненны, а заказчики стали быстрее получать продукты. Как мы это сделали?
1) Поменяли подход к разработке: Scrum вместо Waterfall

Мы кардинально изменили мышление всей компании, пересмотрели подход к заказчикам, разработчикам, пересмотрели документооборот, заново выстроили свой рабочий день. И стали работать над систематизацией процесса.
2) Систематизировали контроль в рамках спринта (Scrum+собственные практики)
Нам нравится гибкость в рамках проекта и регламентированность в рамках спринта — это делает процесс контролируемым. Поэтому мы сделали его максимально прозрачным и легко управляемым.
3) Переработали систему ролей в компании
Появились Product Owner — менеджер проектов с техническими компетенциями и Scrum master — человек, оптимизирующий работу команды.
Внедрили процедуры во время спринта
- Начальное планирование спринта (продумываем бэклог, распределяем время на задачи, ставим дедлайны);
- В процессе (каждое утро) — короткий митап с командой: что будет готово сегодня? что в процессе? какие проблемы?;
- Мониторинг метрик, Burn up chart, коммуникация;
- По окончании спринта ретроспектива: обсуждаем процесс, возникшие проблемы, ставим задачи на следующий спринт.
- Внедрили критерии готовности команды (Definition of Ready)
Визуализируем процесс
Весь процесс отражаем на доске спринта. Показываем объем задач и на кого каждая из них назначена. Участники команды видят загруженность друг друга. Доску заполняем на ретроспективе (в нашем случае это обычная доска со стикерами — так веселее и удобнее), а потом отбрасываем лишнее и переносим в тасктрекер. Там уже детализируем задачу, планируем, сколько часов займет её выполнение.
Для отслеживания продвижения проекта Burnup/burndown chart. Эти диаграммы показывают, какое количество задач сделано и осталось сделать за спринт. Пример burnup:
На графиках виднее, куда движется компания/проект: сколько осталось сделать, сколько предстоит, успевает ли команда к релизу.
По внутренним процессам мы систематизировали все метрики и сделали наглядную графику.
Можно посмотреть загруженность каждого сотрудника и прогресс по его задачам. Полезно выводить визуализацию по отделам в целом.
Ввели критерии готовности функции DoD (Definition of Done)
- Unit-тесты пройдены
- Код исправен
- Функция соответствует описанию (согласованному с заказчиком)
- Функциональные тесты пройдены на всех версиях платформы
- Нефункциональные требования выполнены
- Product Owner согласовал фичу
DoD могут корректироваться в зависимости от проекта. В основном это происходит из-за особенностей работы с серверами и работой со сторонними сервисами.
Масштабирование Scrum на большие проекты
Когда к нам после перехода на Scrum пришли большие проекты, мы столкнулись с трудностями: количество разработчиков в Enterprise проектах сильно превосходит стандартную Scrum-команду, такие проекты устойчивы к изменениям (фокусируются не на гибкости разработки, а на сроках и качестве).
Нужно было сохранить все преимущества команды по Scrum и масштабировать. Мы нашли способ.
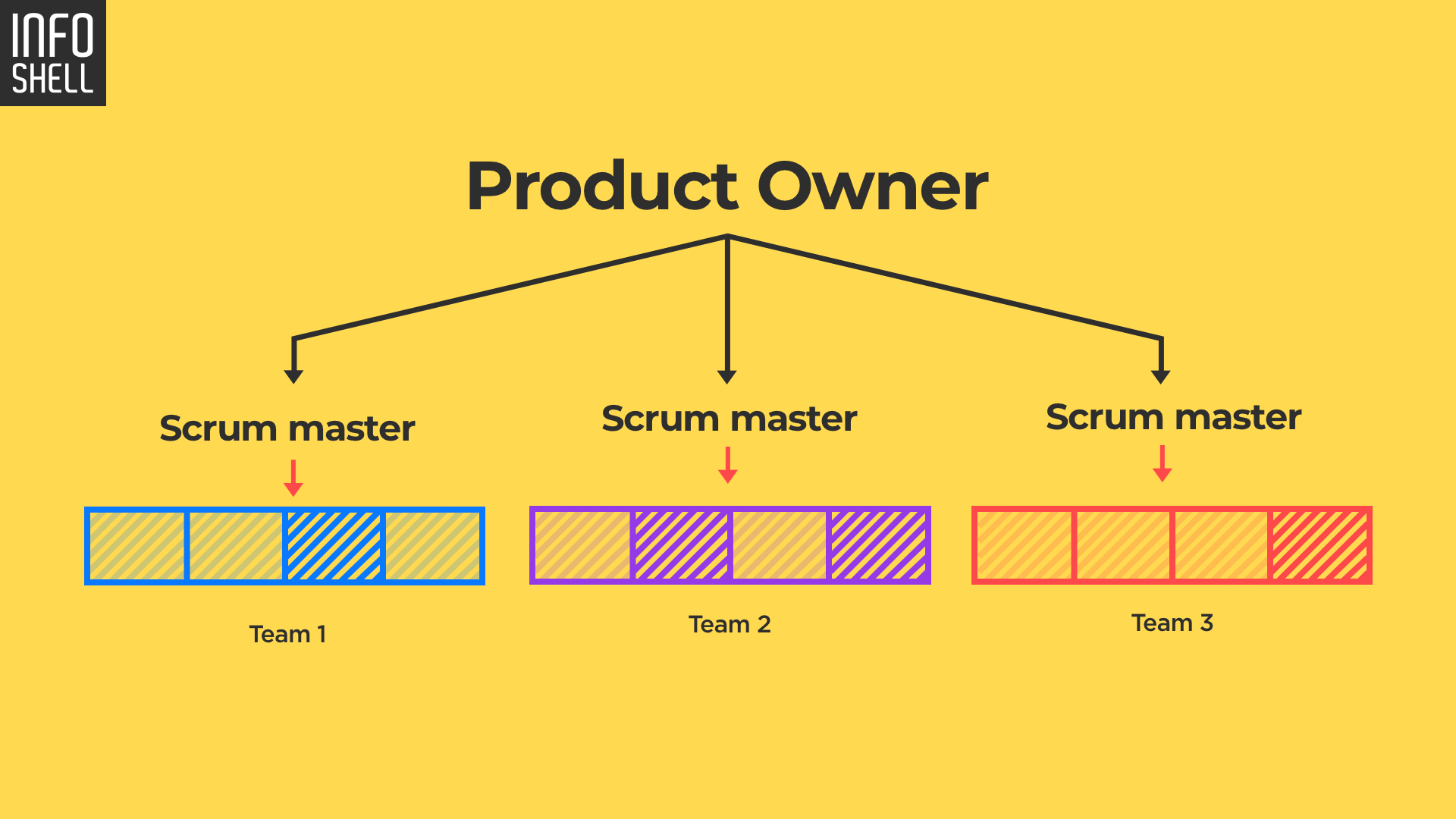
С заказчиком взаимодействует Project Owner (выбираем наиболее компетентного в предметной области проекта). Он ставит задачи менеджерам независимых команд (обычно это Scrum Master), которые выполняют по привычному процессу, с соблюдением процедур Scrum.
В проектах есть два типа спринтов: общие — для всех команд продукта, внутренние — для каждой команды.
На общих ретроспективах встречаются Product Manager и менеджеры команд. Фокус на задачи, которые нельзя решить в пределах одной команды и согласования работ на следующий спринт. Процессы в одном проекте связаны, поэтому это нормально, когда продвижение одной из команд зависит от работы другой.
Прозрачность процесса
Со временем мы поняли, что неэффективно работаем с метриками. Они есть, но что с ними делать — непонятно. И решили, что нужно сделать выгрузку всех данных, пересчитать показатели, наглядно изобразить результаты и сделать их доступными всей компании. Мы перестали ориентироваться на ощущения “кажется, пока на проекте все идет хорошо” и стали оперировать удобно оцифрованной “голой правдой” .
Вдобавок мониторинг загруженности дает возможности моментально перераспределять ресурсы. Мы формируем команды из недозагруженных разработчиков и распределяем по проектам. Раньше это делалось вручную. Все те же данные по отработанным часам подгружаются в бухгалтерию и управленческие отчеты. Мы больше не тратим на это время.
Контроль качества
Когда клиентов стало больше, встал вопрос об оптимизации работы QA-отдела: качеством пренебрегать нельзя, но времени на все проекты не хватает. Наши специалисты перерабатывали. Мы взяли доску, маркер и прикинули, чем занимаются тестировщики. Поняли, что есть три разных ситуации, когда нужен QA, а подход для всех у нас один. Разобрали каждый отдельный случай и вот, что у нас получилось:
Подход 1. В рамках спринта
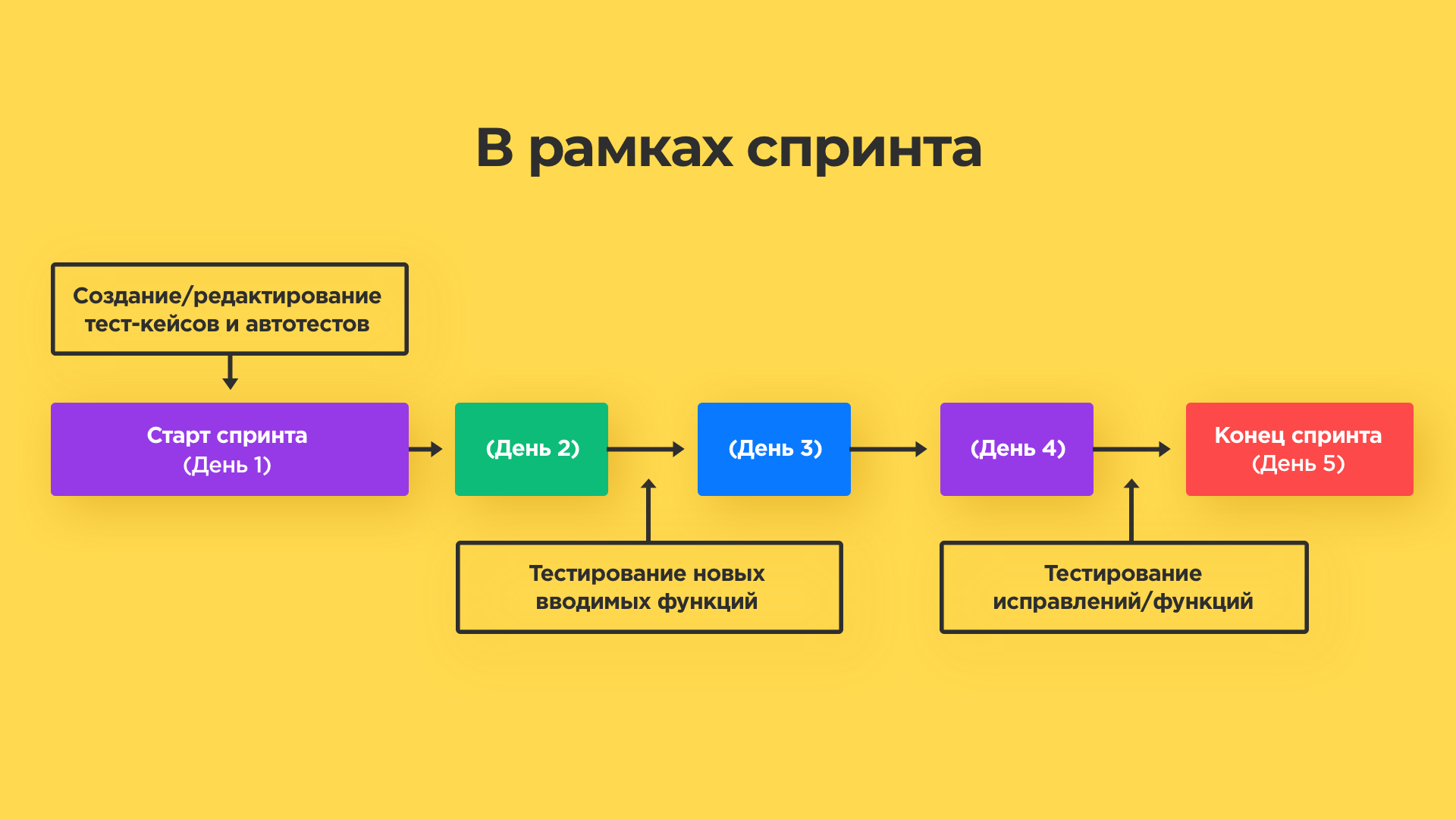
Проводим стандартный цикл тестирования — полное тестирование, затрагивающее основные функции, проверка нового функционала, проверка работы системы со сторонними сервисами, прогон по тест-кейсам, юнит-тесты и т.д. Здесь концентрируемся на работе отдельных частей кода, отвечающих за разные функции. Пускаться в подробности не будем.
Подход 2. В рамках проекта

На проекте возникает момент, когда нужно остановиться и проверить работу всей системы в целом. Раньше мы делали это по мере разработки, иногда в самом конце — это зависело от проекта. И часто такой подход выходил нам боком. Мы вывели его в отдельный этап и заметно сократили загруженность тестировщиков в конце проекта, распределив скоуп работ по разным этапам. Плюс, это сократило работу разработчикам: крупные баги стали выявляться раньше, и их стали фиксить до того, как сверху накладывали дополнительный функционал.
Подход 3. Предрелизный спринт
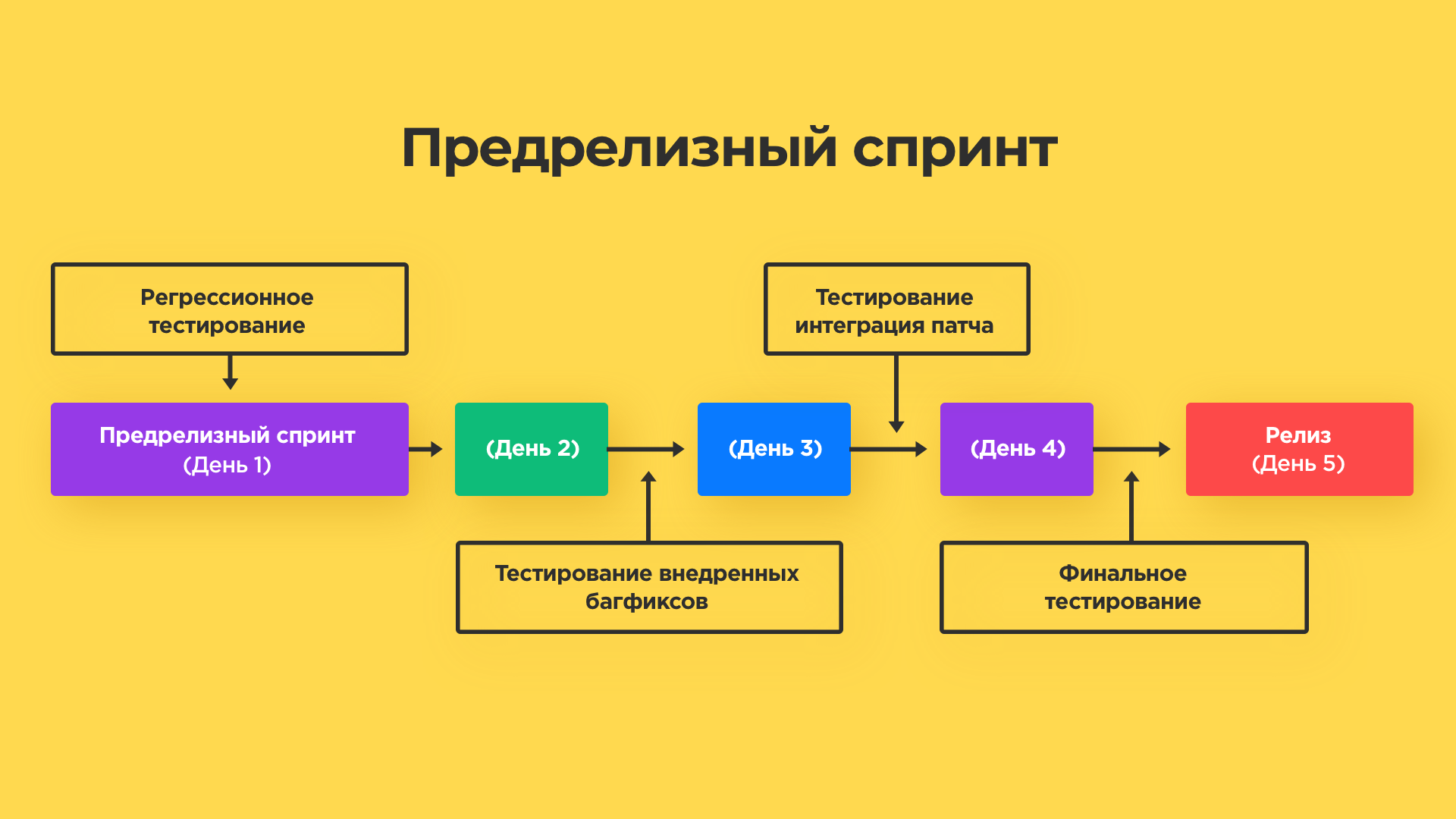
Тот самый спринт перед выпуском приложения, когда наваливаются последние “мелкие” фичи. Во-первых, мы разгрузили этот этап предыдущим. Во вторых, структурировали процесс. На этом этапе делаем акцент на работу всей системы: как она работает со сторонними сервисами, не повлияли ли внесенные изменения на работу других функций приложения, обновляются ли базы данных и т.д.
Подход 4. «Тестирование на поддержке»
Это для случаев, когда мы контролируем работу уже готового приложения и дописываем его по обращению заказчика. После обновления приложения проводим тестирование новой функции, а дальше — тестирование сборки в целом. Т.е. повлиял ли новый функционал на работу основных функций. Если да, возвращаемся к подходу “в рамках спринта”.
Создание внутренних программ обучения и наставничества
Рост компании также сопровождается приходом новых сотрудников, и нужно обучать одному и тому же новых людей. Начала формироваться база знаний, которую мы настраиваем в вики-системе. Каждый новый сотрудник получает стартовый пакет документов. В нем стандарты проведения процедур, документы по его специальности, тренинги, наработки.
В перспективе в каждом отделе будет человек, ответственный за улучшение базы знаний. Он ставит эту задачу на кого-то экспертного в узкой области. Эксперт оформляет документ, в нем нужные ссылки и любые полезные файлы.
Мы прописали карьерную лестницу для всех сотрудников. Для разработчиков она всегда примерно одинаковая. С менеджерами проектов дела сложнее: у каждой компании свои требования и компетенции. О них поговорим позже. В этих документах подробно описан взгляд компании на то, какие скиллы нужны для каждого уровня и отработанный стаж, чтобы продвинуться дальше. Для разработчика это язык программирования, конкретные навыки в каждом из них и стаж в компании. Это устанавливает рамки: каждый точно знает, на какой уровень заработной платы может претендовать и как двигаться дальше.
Развитие не только как исполнителя, но и как компании
Мы брали все заказы, которые обещали стабильные инвестиции . И поняли, что хотим большего. Поэтому выбрали три основных направления: E-commerce и Marketplace, Fintech, Стартапы.
И стали наращивать компетенции. Развиваем потенциал сотрудников в этих областях, формируем узкопрофильные команды, делаем собственные проекты по сферам, формируем команду на западный рынок — движемся.
Каждый пункт статьи — результат преодоления костылей, которые мешают двигаться. Сейчас мы растем, расширяем штат, достигаем поставленных целей и хотим больше — значит, все делаем правильно.



